Mistakes happen in the course of data entry. A research coordinator, intending to input a weight of 80 kilograms, leaves the field before striking the “0” key. Her colleague, completing a field for temperature, enters a value of 98, forgetting that the system expects the measurement in Celcius. But no adult enrolled in a clinical study weighs 8 pounds. And the patient with a body temp of 98 degrees Celsius? Fever is something of an understatement!
Left standing, errors like the ones above distort analysis. That’s why data managers spend so much time reviewing submitted data for reasonableness and consistency. What if it were possible to guard against introducing error in the first place? With electronic forms, it is possible.

“Edit checks,” sometimes called “constraints” or “validation,” automatically compare inputted values with criteria set by the form builder. The criteria may be a set of numerical limits, logical conditions, or a combination of the two. If the inputted value violates any part of the criteria, a warning appears, stating why the input has failed and guiding the user toward a resolution (without leading her toward any particular replacement).
Edit checks may be simple or complex; evaluate a single item or a group of related items; prevent the user from moving on or simply raise a flag. You can learn all about these differences below. The goals of edit checks are universal: higher data quality right from the start!
1. Check yourself
Setting edit checks appropriately is all about balance. Place too many checks, or impose ranges that are especially narrow, and you’ll end up raising alarms for a lot of data that’s perfectly valid. That will slow down research coordinators who simply want to get you the data you need. Place too few checks, or allow any old values, and you’ll open the gates to a flood of nonsensical data. You or a data manager colleague will then need to address this data with the clinical site after it’s submitted. Wait too long, and you could discover that the site can’t determine what led to the error in the first place.
While there’s no exact formula for striking the right balance, there are guidelines. Any value that could signal a safety issue ought to receive a lot of scrutiny. For example, in a study investigating a compound known to impact kidney function, you’ll want to place careful constraints around an item asking for a glomerular filtration rate. The same goes for measures tied to eligibility or constitutive of primary endpoints. On the other hand, it doesn’t make sense to enforce a value for height that’s within 10% of a population mean. Moderately short and tall people enroll in studies, too!
All edit checks share the common objective of cleaner data at the point of entry. They also share a rigorous and logical method. Input is either valid or not, and the determination is always objective. Beyond this family resemblance, though, edit checks differ in their scope and effects.
2. Hard vs. soft
Hard edit checks prevent the user inputting data from proceeding to the next item or item group. Note that a validated system will never expunge a value once submitted, even if it violates a hard check. Rather, it will automatically append a query to the invalid data. Until the query is resolved, the form users won’t be able to advance any further on the form.
Soft edit checks, by contrast, allow the user to continue through the form. However, the user won’t be able to mark the form complete until the query attached to the check is resolved.
Hard and soft edit checks each have their place. If an out of range value would preclude further study activities, a hard edit check may be justified, as it sends a conspicuous “stop and reassess” message to the clinical research coordinator. Where an invalid piece of data is likely to represent a typo or misunderstanding (e.g. a height of 6 meters as opposed to 6 feet entered on a physical exam form), a soft edit check is preferable.
3. Univariate vs. multivariate
Univariate edit checks evaluate input against range or logical constraints for a single item–for example, the value for Height, in inches, must be between 48 and 84.
Multivariate edit checks, by contrast, place constraints on the data inputted for two or more fields. “If, then” expressions often power these checks: if field A is selected, or holds a value within this range, then field B must meet some related set of criteria. If a form user indicates a history of cancer for a study participant, a related field asking for a diagnosis will fire its edit check if a cancer diagnosis isn’t provided.
When input fails to meet a multivariate edit check, it’s important for the warning message to state which item values are responsible for the conflict. Suppose a research coordinator enters “ovarian cyst” on a medical history form for a participant previously identified as male. A well-composed error message on the medical history item will refer the user to the field for sex.
4. Standard vs. protocol-specific
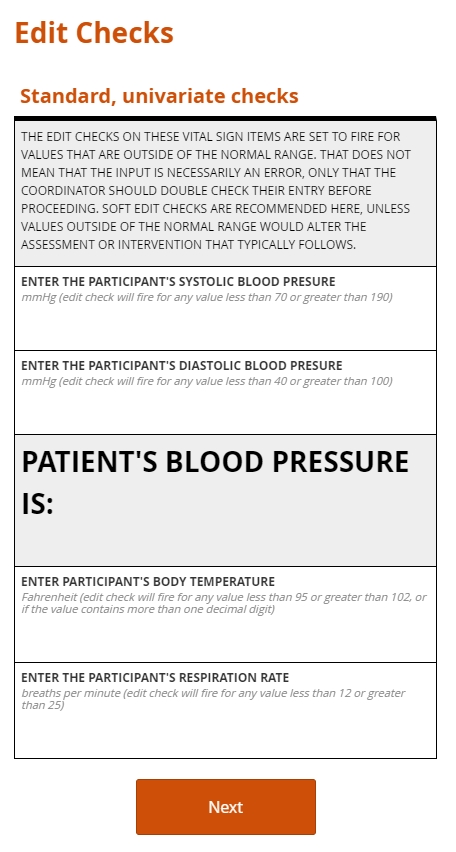
Standard edit checks, such as those placed on items for routine vital signs, do not vary from study to study. Their value lies in their re-usability. Consider a check placed on the item for body temperature within a Visit 1 Vital Signs form; one, say, that sets a range between 96 and 100 degrees Fahrenheit. That check can follow that item from form to form, just as the form may be able to follow the Visit 1 event from study to study. There are no experimental reasons to set a range wider or more narrow than this commonly expected one.
A protocol-specific edit, by contrast, enforces on an item a limit or threshold dictated by the protocol. Imagine a study to determine the reliability of a diagnostic tool for prostate cancer in men at least 50 years old. The eligibility form for such a study will likely include protocol-specific edit checks on the items for participant sex and date of birth. Or consider an infectious disease study whose patient population requires careful monitoring of their ALT value. In this context, a value that’s just slightly above normal may indicate an adverse event, so the acceptable range would be set a lot narrower than it would be for, say, an ophthalmological study.
5. Query, query (when data’s contrary)
A research coordinator who enters invalid data may not know how to correct their input, even with the guidance of the warning message. Or their input may be perfectly accurate and intended, while still falling outside the range encoded by the edit check. In these cases, your EDC should generate a query on the item. Queries are virtual “red flags” that attend any piece of data that either:
- fails to meet the item’s edit check criteria
- raises questions for the data manager or data reviewer
The first kind of query, called an “auto-query,” arises from programming. The system itself flags the invalid data and adds it to the log of queries that must be resolved before the database can be considered locked. The second kind of query, called a “manual query,” starts when a human, possessing contextual knowledge the system lacks, indicates her skepticism concerning a value. Like auto-queries, manual queries must be resolved before the database can be locked.
To resolve or “close” an auto-query, the user who first entered the invalid data (or another study team member at the clinical site) must either:
- submit an updated value that meets the edit check criteria
- communicate to the data manager that the flagged data is indeed accurate, and should stand
The data manager may close a query on data that violates an edit check. In these cases, she is overriding the demands of the validation logic, but only after careful consideration and consultation with the site.
To resolve a manual query, the site user and data manager engage in a virtual back and forth–sometimes short, sometimes long–to corroborate the original value or arrive at a correction. A validated EDC will log each question posed and answered during this exchange, so that it’s possible to reconstruct when and why the value under consideration changed as a result.
Resolving a query isn’t just a matter of removing the red flag. If the data manager accepts the out of range value, she must indicate why. If the research coordinator inputs a corrected value, she too must supply a reason for the change as part of the query back and forth. The goal is to arrive at the truth, not “whatever fits.”